おはこんばんにちは。前回、競走馬の馬体写真からCNNを用いて順位を予想するモデルを構築しました。結果は芳しくなく、特にshap値を用いた要因分析を行うと馬体よりも背景の厩舎に反応している様子が見えたりと分析の精緻化が必要となりました。今回はPytorchのPre-trainedモデルを用いて馬体写真から背景を切り出し、馬体のみとなった写真で再分析を行いたいと思います。
1. Pre-trainedモデルのダウンロード
コードはこちらのものを参考にしています。まず、パッケージをインストールします。
import numpy as np
import cv2
import matplotlib.pyplot as plt
import torch
import torchvision
from torchvision import transforms
import glob
from PIL import Image
import PIL
import os学習済みモデルのインストールを行います。
#学習済みモデルをインストール
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torchvision.models.segmentation.deeplabv3_resnet101(pretrained=True)
model = model.to(device)
model.eval()## DeepLabV3(
## (backbone): IntermediateLayerGetter(
## (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
## (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
## (layer1): Sequential(
## (0): Bottleneck(
## (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
## (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## (downsample): Sequential(
## (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## )
## )
## (1): Bottleneck(
## (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
## (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (2): Bottleneck(
## (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
## (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## )
## (layer2): Sequential(
## (0): Bottleneck(
## (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
## (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## (downsample): Sequential(
## (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
## (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## )
## )
## (1): Bottleneck(
## (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
## (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (2): Bottleneck(
## (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
## (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (3): Bottleneck(
## (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
## (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## )
## (layer3): Sequential(
## (0): Bottleneck(
## (conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## (downsample): Sequential(
## (0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## )
## )
## (1): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (2): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (3): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (4): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (5): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (6): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (7): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (8): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (9): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (10): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (11): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (12): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (13): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (14): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (15): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (16): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (17): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (18): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (19): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (20): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (21): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (22): Bottleneck(
## (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## )
## (layer4): Sequential(
## (0): Bottleneck(
## (conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
## (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## (downsample): Sequential(
## (0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## )
## )
## (1): Bottleneck(
## (conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
## (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## (2): Bottleneck(
## (conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
## (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (relu): ReLU(inplace=True)
## )
## )
## )
## (classifier): DeepLabHead(
## (0): ASPP(
## (convs): ModuleList(
## (0): Sequential(
## (0): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (2): ReLU()
## )
## (1): ASPPConv(
## (0): Conv2d(2048, 256, kernel_size=(3, 3), stride=(1, 1), padding=(12, 12), dilation=(12, 12), bias=False)
## (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (2): ReLU()
## )
## (2): ASPPConv(
## (0): Conv2d(2048, 256, kernel_size=(3, 3), stride=(1, 1), padding=(24, 24), dilation=(24, 24), bias=False)
## (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (2): ReLU()
## )
## (3): ASPPConv(
## (0): Conv2d(2048, 256, kernel_size=(3, 3), stride=(1, 1), padding=(36, 36), dilation=(36, 36), bias=False)
## (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (2): ReLU()
## )
## (4): ASPPPooling(
## (0): AdaptiveAvgPool2d(output_size=1)
## (1): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (3): ReLU()
## )
## )
## (project): Sequential(
## (0): Conv2d(1280, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
## (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (2): ReLU()
## (3): Dropout(p=0.5, inplace=False)
## )
## )
## (1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
## (2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (3): ReLU()
## (4): Conv2d(256, 21, kernel_size=(1, 1), stride=(1, 1))
## )
## (aux_classifier): FCNHead(
## (0): Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
## (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
## (2): ReLU()
## (3): Dropout(p=0.1, inplace=False)
## (4): Conv2d(256, 21, kernel_size=(1, 1), stride=(1, 1))
## )
## )どうやら全てのPre-trainedモデルは、同じ方法で正規化された形状\((N, 3, H, W)\)の3チャンネルRGB画像のミニバッチを想定しているようです。ここで\(N\)は画像の数、\(H\)と\(W\)は少なくとも224ピクセルであることが想定されています。画像は、[0, 1]の範囲にスケーリングされ、その後、平均値=[0.485, 0.456, 0.406]と標準値=[0.229, 0.224, 0.225]を使用して正規化される必要があります。ということで、前処理を行う関数を定義します。
#前処理
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])2. 背景削除処理の実行
では、前回記事のseleniumを用いたコードで収集した画像を読み込み、1枚1枚背景削除処理を行っていきます。
#フォルダを指定
folders = os.listdir(r"C:\Users\aashi\umanalytics\photo\image")
#それぞれのフォルダから画像を読み込み、Image関数を使用してRGB値ベクトル(numpy array)へ変換
for i, folder in enumerate(folders):
files = glob.glob("C:/Users/aashi/umanalytics/photo/image/" + folder + "/*.jpg")
index = i
for k, file in enumerate(files):
img_array = np.fromfile(file, dtype=np.uint8)
img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
h,w,_ = img.shape
input_tensor = preprocess(img)
input_batch = input_tensor.unsqueeze(0).to(device)
with torch.no_grad():
output = model(input_batch)['out'][0]
output_predictions = output.argmax(0)
mask_array = output_predictions.byte().cpu().numpy()
Image.fromarray(mask_array*255).save(r'C:\Users\aashi\umanalytics\photo\image\mask.jpg')
mask = cv2.imread(r'C:\Users\aashi\umanalytics\photo\image\mask.jpg')
bg = np.full_like(img,255)
img = cv2.multiply(img.astype(float), mask.astype(float)/255)
bg = cv2.multiply(bg.astype(float), 1.0 - mask.astype(float)/255)
outImage = cv2.add(img, bg)
Image.fromarray(outImage.astype(np.uint8)).convert('L').save(file)行っている処理はPre-trainedモデルで以下のようなmask画像を出力し、実際の画像のnumpy配列とmask画像を統合して、背景削除画像を生成しています。出力例は以下のような感じです。
plt.gray()
plt.figure(figsize=(20,20))
plt.subplot(1,3,1)
plt.imshow(img)
plt.subplot(1,3,2)
plt.imshow(mask)
plt.subplot(1,3,3)
plt.imshow(outImage)
plt.show()
plt.close()フォルダはこんな感じです。うまく処理できているものもあれば調教師の方が映ってしまっているのもありますね。物体を識別して、馬だけをmaskする方法もあるとは思いますがこのモデルでは物体のラベリングまではできないのでこのまま進みます。

フォルダ
3. CNNを用いた分析
ここからは前回記事と同じ内容です。結果のみ掲載します。
## Test accuracy: 0.2711864406779661## <sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay object at 0x0000000026C4C488>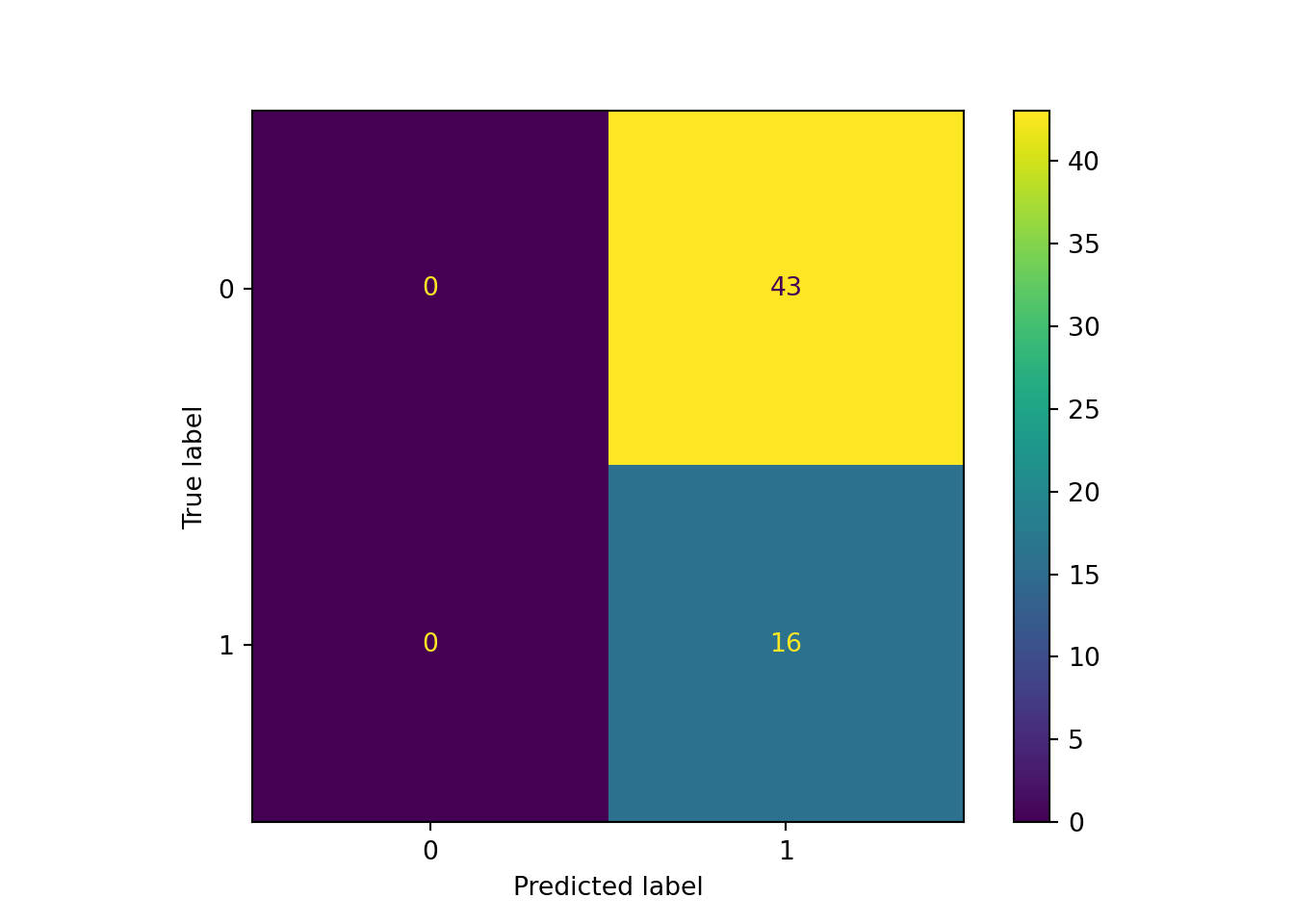
散々な結果になりました。 まったく識別できていません。馬体写真には順位を予測するような特徴量はないんでしょうか。それともG1の出走馬ではバラツキがなく、識別不可能なのでしょうか。いずれいにせよ、ちょっと厳しそうです。
4. Shap値を用いた結果解釈
前回同様、どのように失敗したのかshap値を使って検証してみましょう。この画像を例として使います。
plt.imshow(X_test[4])
plt.show()
plt.close()import shap
background = X_resampled[np.random.choice(X_resampled.shape[0],100,replace=False)]
e = shap.GradientExplainer(model,background)
shap_values = e.shap_values(X_test[[4]])
shap.image_plot(shap_values[1],X_test[[4]])## Traceback (most recent call last):
## File "C:\Users\aashi\Anaconda3\envs\umanalytics\lib\site-packages\matplotlib\backends\backend_qt5.py", line 496, in _draw_idle
## self.draw()
## File "C:\Users\aashi\Anaconda3\envs\umanalytics\lib\site-packages\matplotlib\backends\backend_agg.py", line 393, in draw
## self.figure.draw(self.renderer)
## File "C:\Users\aashi\Anaconda3\envs\umanalytics\lib\site-packages\matplotlib\artist.py", line 38, in draw_wrapper
## return draw(artist, renderer, *args, **kwargs)
## File "C:\Users\aashi\Anaconda3\envs\umanalytics\lib\site-packages\matplotlib\figure.py", line 1736, in draw
## renderer, self, artists, self.suppressComposite)
## File "C:\Users\aashi\Anaconda3\envs\umanalytics\lib\site-packages\matplotlib\image.py", line 137, in _draw_list_compositing_images
## a.draw(renderer)
## File "C:\Users\aashi\Anaconda3\envs\umanalytics\lib\site-packages\matplotlib\artist.py", line 38, in draw_wrapper
## return draw(artist, renderer, *args, **kwargs)
## File "C:\Users\aashi\Anaconda3\envs\umanalytics\lib\site-packages\matplotlib\axes\_base.py", line 2590, in draw
## self._update_title_position(renderer)
## File "C:\Users\aashi\Anaconda3\envs\umanalytics\lib\site-packages\matplotlib\axes\_base.py", line 2531, in _update_title_position
## if (ax.xaxis.get_ticks_position() in ['top', 'unknown']
## File "C:\Users\aashi\Anaconda3\envs\umanalytics\lib\site-packages\matplotlib\axis.py", line 2153, in get_ticks_position
## self._get_ticks_position()]
## File "C:\Users\aashi\Anaconda3\envs\umanalytics\lib\site-packages\matplotlib\axis.py", line 1843, in _get_ticks_position
## minor = self.minorTicks[0]
## IndexError: list index out of range
前足から顔にかけてを評価しているようです。意外に臀部を評価している様子はありません。 各層において画像のどの側面を捉えているかを可視化してみたいと思います。
from keras import models
layer_outputs = [layer.output for layer in model.layers[:8]]
layer_names = []
for layer in model.layers[:8]:
layer_names.append(layer.name)
images_per_row = 16
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)
activations = activation_model.predict(X_train[[0]])
for layer_name, layer_activation in zip(layer_names, activations):
n_features = layer_activation.shape[-1]
size = layer_activation.shape[1]
n_cols = n_features // images_per_row
display_grid = np.zeros((size * n_cols, images_per_row * size))
for col in range(n_cols):
for row in range(images_per_row):
channel_image = layer_activation[0,
:, :,
col * images_per_row + row]
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype('uint8')
display_grid[col * size : (col + 1) * size,
row * size : (row + 1) * size] = channel_image
scale = 1. / size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid, cmap='viridis')
plt.show()
plt.close()







こっちはやっぱり分からないですね。
まとめ
厩舎背景を削除し、再実行してみましたが結果変わらずでした。PyTorchを使ったり、背景削除を行ういい経験にはなりましたが結果は伴わずということで馬体写真はいったんここでストップです。